In 2024, the "Hello World" of AI was a chatbot. You typed, "Write me a poem," and you watched the cursor blink as the words appeared. It was magical. It was also incredibly inefficient.
Now, in early 2026, the "Chat UI" is increasingly seen as an anti-pattern for serious work.
If I hire a human accountant, I don't sit in their office and watch them type numbers into Excel. I hand them a stack of receipts, I leave, and they email me when the tax return is done.
Agentic AI works the same way. The most successful products launching this year aren't designed for conversation; they are designed for delegation.
If you are building software in 2026, your roadmap needs to shift from Synchronous Interaction (User clicks → System responds) to Asynchronous Execution (User goals → System works → System notifies).
Here is the 4-step roadmap for building software that works while your users sleep.
1. The UX Shift: Kill the Loading Spinner
For 20 years, web development was about reducing latency. We optimized database queries to shave off milliseconds because "speed equals conversion."
With Agentic AI, latency is a feature, not a bug.
Reasoning takes time. Planning takes time. Self-correction takes time. A complex supply-chain optimization agent might need 45 minutes to run its simulations.
If you put a loading spinner on the screen for 45 minutes, your user will leave.
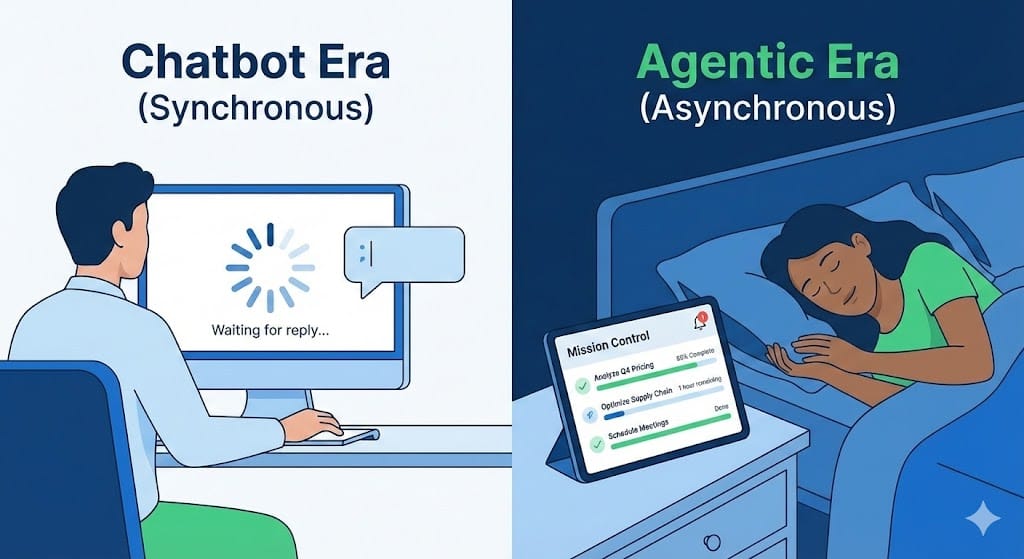 Figure 1: The "Sleep Test" - If your software requires the user to stare at a screen, it's not agentic.
Figure 1: The "Sleep Test" - If your software requires the user to stare at a screen, it's not agentic.The New Pattern: The "Mission Control" Dashboard
- Don't: Show a chat window waiting for a reply.
- Do: Show a "Job Queue."
Example: "Agent started: Analyze Q4 Competitor Pricing. Status: Browsing 14 sites... Estimated completion: 20 mins."
Your product needs to feel less like a chat app and more like a command center. The user sets the parameters, authorizes the budget, and hits "Deploy." The app then moves the task to the background and sends a push notification when it's done.
2. Architecture: "Human-in-the-Loop" as a Tool
The biggest lie of 2025 was "Fully Autonomous."
The reality of 2026 is "Supervised Autonomy."
Agents get stuck. They encounter ambiguous data. They hit 404 errors. If your agent fails silently, you lose trust. If it bugs the user for every little thing, you lose utility.
You need to design Human-in-the-Loop (HITL) not as a failure state, but as a standard "tool" in the agent's toolkit.
The Pattern:
- Agent hits an ambiguity: "I found two pricing PDFs. Which one is the primary source?"
- Agent pauses execution (state is persisted).
- User gets a "Clarification Request" (not an error message).
- User selects Option A.
- Agent resumes.
In your codebase, AskHuman() should be an API call just like FetchWeather() or QueryDatabase().
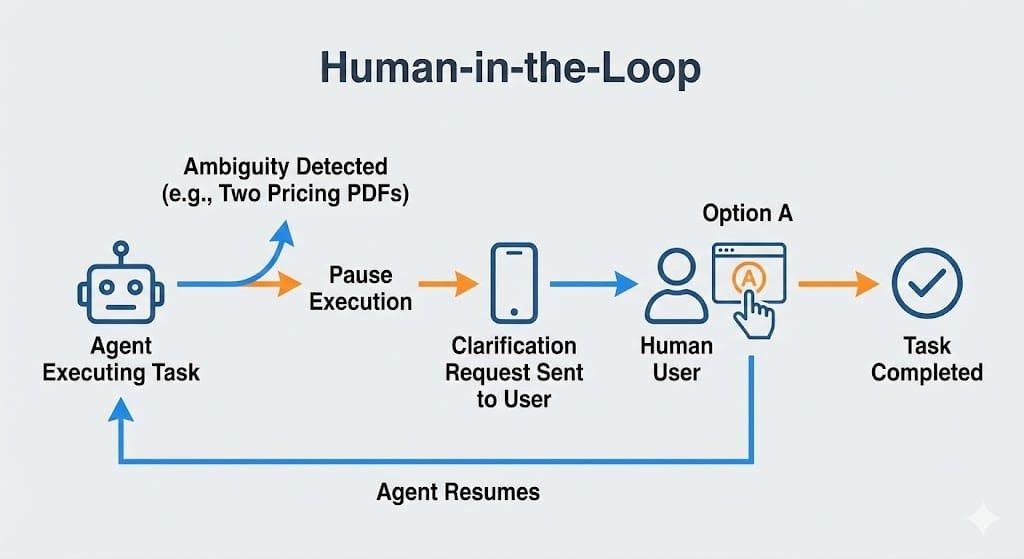 Figure 2: Human-in-the-Loop as a Function - Treating human intervention as a structured API call.
Figure 2: Human-in-the-Loop as a Function - Treating human intervention as a structured API call.3. FinOps: The "Infinite Loop" Bankruptcy Risk
In traditional software, an infinite loop freezes the browser.
In Agentic software, an infinite loop burns a hole in your bank account.
We are seeing a massive rise in Agentic FinOps. Since agents use "Chain-of-Thought" and iterative tool usage, a buggy agent can rack up thousands of token costs in minutes by arguing with itself or retrying a failed API call 500 times.
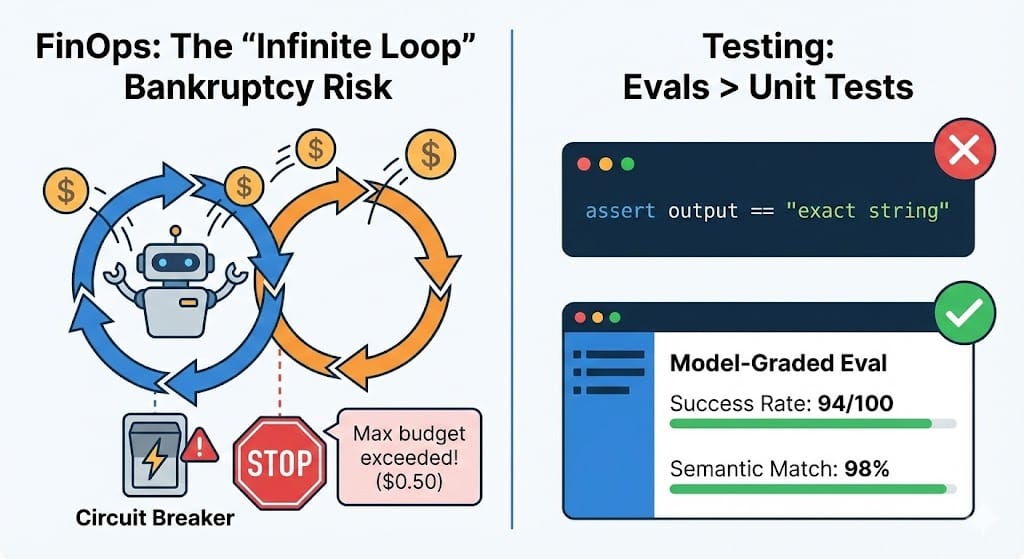 Figure 3: The "Infinite Loop" Risk - Why Agentic FinOps requires strict budget caps and circuit breakers.
Figure 3: The "Infinite Loop" Risk - Why Agentic FinOps requires strict budget caps and circuit breakers.The Guardrails:
- Circuit Breakers: Hard limits on steps per run (e.g., "Max 50 steps").
- Budget Caps: "This task is authorized for $0.50 of compute. If it exceeds that, pause and ask for approval."
- Loop Detection: Heuristics to catch when an agent is repeating the same error message.
4. Testing: Evals > Unit Tests
You cannot write a unit test for "vibes."
Traditional TDD (Test Driven Development) breaks down when the output is non-deterministic.
If you ask an agent to "summarize this email," it will use different words every time. assert output == expected_string will fail 99% of the time.
The Shift to "Evals" (Evaluations):
- Model-Graded Evals: Use a stronger model (e.g., GPT-5 or Gemini Ultra) to grade the work of your smaller production model.
- Semantic Similarity: Check if the meaning matches, not the text.
- Success Rate Metrics: Instead of "Did it pass?", track "Success Rate over 100 runs." If the agent successfully booked the flight 94/100 times, is that good enough for production? (Hint: For booking flights, no. For generating images, yes).
The Bottom Line
The "Chatbot Era" was about the Input (Prompt Engineering).
The "Agentic Era" is about the Process (Observability, State Management, and Guardrails).
Stop building tools that wait for the user to type. Start building tools that work while the user is doing something else.
Upcoming
Focus: We dive into the "Vertical AI" trend—why specific, narrow agents are beating general-purpose models in the enterprise.