As we pack up for the New Year and look back at the carnage of failed AI pilots in 2025, a painful truth is emerging.
We spent the last 12 months obsessing over the engine. We argued about Gemini vs. GPT-5. We debated parameters, reasoning capabilities, and context windows. We treated the models like race cars, tweaking the aerodynamics to get an extra 1% of performance.
But as we head into 2026, we are realizing that our race cars are sitting in the garage. Not because the engines are broken, but because we have no clean fuel to put in them.
The AI crisis of 2026 won't be about intelligence; it will be about Data Governance. We hit the "Data Wall," and it hurt.
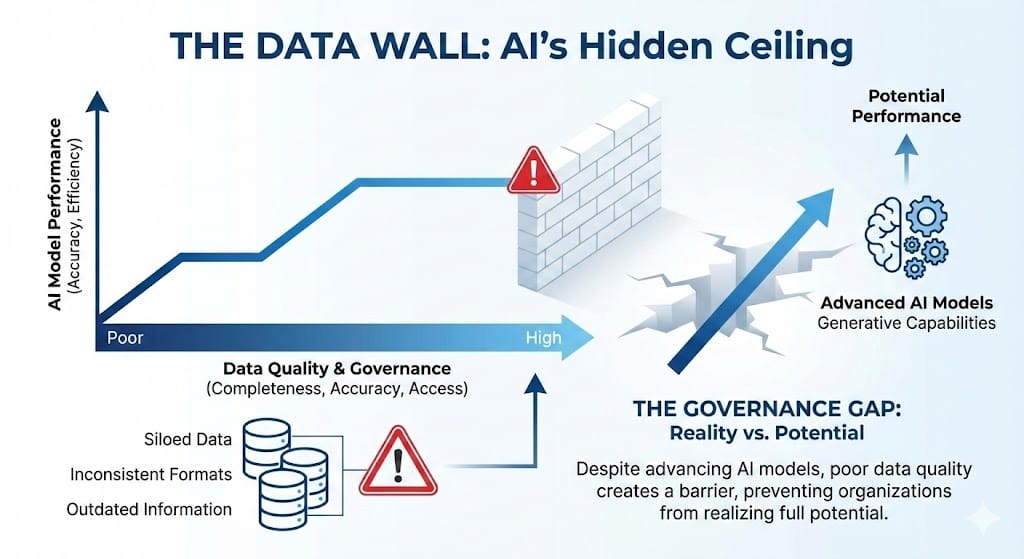 Figure 1: The "Data Wall" - AI models hit a ceiling not due to intelligence limitations, but data quality constraints.
Figure 1: The "Data Wall" - AI models hit a ceiling not due to intelligence limitations, but data quality constraints.The Hangover: The "Vector Dumpster"
In the frantic Gold Rush of 2024 and early 2025, the strategy for Enterprise AI was simple: RAG (Retrieval-Augmented Generation).
The playbook was crude: take every PDF, Slack message, and Notion doc in the company, chop it up, embed it, and throw it into a Vector Database.
We didn't build knowledge bases; we built Vector Dumpsters.
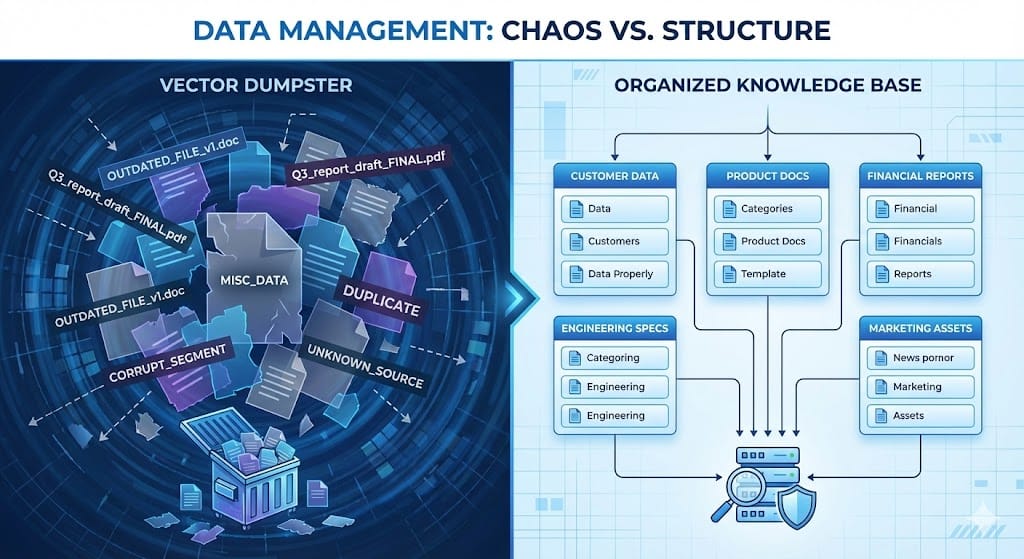 Figure 2: Vector Dumpster vs. Curated Knowledge Base - The difference between throwing data in and organizing it properly.
Figure 2: Vector Dumpster vs. Curated Knowledge Base - The difference between throwing data in and organizing it properly.Now, your internal AI agent is confident, but it's dangerously wrong. It's quoting the pricing policy from 2023 because that PDF was never deleted. It's conflating the "Q3 Marketing Strategy" with the "Q3 Engineering Handoff" because they use similar keywords.
The "Data Drift" is real. The world changed, but your Vector Database stayed frozen in 2024.
The 2026 Trend: Data Fabric & The "Golden Record"
If 2025 was about accumulating data, 2026 will be about curating it.
We are seeing a massive pivot toward Data Fabric architectures. Instead of moving data into a central swamp (where it rots), we are leaving data where it lives—in Salesforce, in Snowflake, in Jira—and building a semantic layer on top.
The shift for Data Engineers:
Old Way: "ETL everything into the Vector DB."
New Way: "Federated retrieval." The AI queries the live system of record. It doesn't ask the Vector DB what the customer's balance is; it uses a tool to ask the Billing API directly.
This is the only way to solve the hallucination problem. The "Golden Record" isn't a cached embedding; it's the live reality.
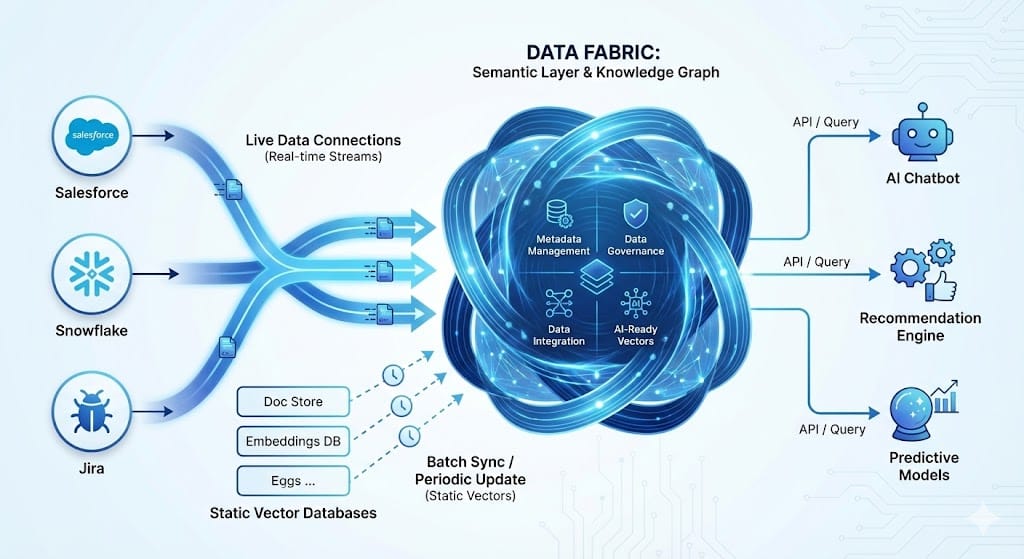 Figure 3: Data Fabric Architecture - Federated retrieval from live systems vs. stale vector databases.
Figure 3: Data Fabric Architecture - Federated retrieval from live systems vs. stale vector databases.The PM Angle: Trust is a UX Feature
For Product Managers, this data crisis manifests as a Trust Crisis.
Users are tired of double-checking the AI. If they have to verify every output, the AI isn't saving them time—it's giving them homework.
In 2026, "Citation" is no longer a nice-to-have; it is the primary UX requirement.
- Explainability: Don't just give the answer. Show the lineage. "I found this answer in the '2025 Q4 Policy Update' document, authored by Sarah Jenkins on Nov 12th."
- Confidence Scores: We need to surface the AI's uncertainty. If the data is messy, the UI should reflect that ambiguity (e.g., "I found conflicting data in these two sources...").
The Bottom Line
We spent 2024 and 2025 acting like Formula 1 drivers, obsessed with speed and models.
2026 is the year we all become plumbers.
It's unglamorous work. It involves cleaning metadata, enforcing retention policies, and untangling permission structures. But it is the only way forward.
The companies that win next year won't have the smartest AI. They will have the cleanest data.
Happy New Year. Let's get cleaning.
Coming Next
Coming in Jan 2026: The "Agentic" Roadmap—How to plan for software that works while you sleep.